ClaudeDevKit:一个面向 Claude Code CLI 的轻量 AI 协作工作流实践
为什么做这个项目
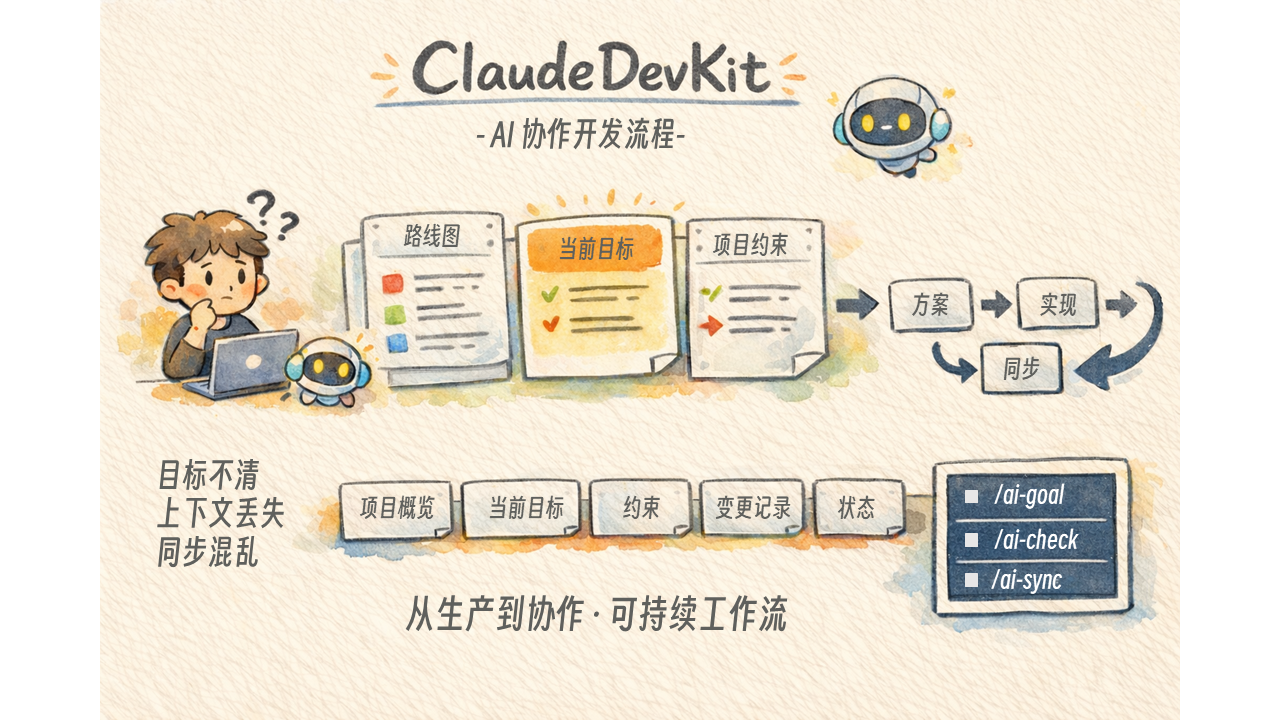
在使用Claude Code Cli进行开发的时候,即使工具本身已经非常强大,但如果不对项目提前进行规划,而是通过多轮对话进行“对话式”开发,那么往往会有如下问题:
- AI失焦:比如在开头告诉了AI,修改完之后,严禁自己提交。但偶尔会忘掉该约束。
- 上下文漂移:随着对话轮次增加,AI更容易被后续局部任务“带偏”,遗忘最初设定的全局目标、边界条件或编码规范,最后虽然局部修改看起来合理,但整体实现已经偏离预期。
- 修改失控:缺少前期拆解和任务边界约束时,AI容易为了“顺手修好”相关问题而扩大改动范围,导致本来只想做小修小补,最后却引入额外重构、影响未涉及模块,增加回归和排查成本。
例如:
1 | 用户:帮我优化一下用户模块的性能 |
引言
ClaudeDevKit 不是业务框架,也不是自动生成代码的平台。它更像是我在使用 Claude Code CLI 过程中,为了解决“AI 能写代码,但不一定能稳定协作”这个问题,专门整理出来的一套轻量工作流骨架。
这个项目想解决的核心问题不是“如何让 AI 多写一点”,而是:
-
如何让 AI 始终围绕当前目标工作
-
如何让 AI 在实现前先经过需求澄清和方案确认
-
如何让路线图、当前状态、约束、测试、同步形成闭环
-
如何把 AI 从一次性问答工具,变成可持续参与项目迭代的协作者
在我的理解里,ClaudeDevKit 就是在尝试给这种AI开发能力提供一个足够轻、但又足够稳定的组织方式。
设计目标
这个项目的设计目标很明确:
-
用最少的文档和目录结构,给 AI 提供稳定上下文。
-
把长期规划和当前执行拆开,减少上下文漂移。
-
把“先确认目标,再进入实现”固化成流程约束。
-
让实现结束后的检查、同步、提交形成明确边界。
-
保持轻量,能够嵌入已有项目,而不是强迫项目迁移到某个大系统里。
因此,这个仓库的重点不在业务代码,而在工作流定义本身。
仓库结构与职责划分
整个仓库主要分成两层:
-
docs/ai/:存放共享状态和项目事实 -
.claude/:存放命令入口、skills 和 agents 定义
docs/ai/:共享状态层
这部分文件是 AI 和开发者共享的上下文载体:
docs/ai/roadmap.md
记录总体技术设计、阶段目标、依赖关系和长期进度,是长期事实来源。
docs/ai/current-goal.md
记录当前唯一活跃目标的设计、步骤、任务、测试计划和同步说明,是当前执行上下文。
docs/ai/current-goal.state.yaml
记录当前目标的机器可读状态,例如 empty、discover、design、confirm_plan、implement、sync。
docs/ai/project-summary.md
记录面向 AI 的项目摘要,帮助快速理解当前项目结构和意图。
docs/ai/project-tree.md
记录高价值目录树、关键入口和关键配置文件。
docs/ai/change-log.md
记录目标完成后的变更摘要、测试结果、安全结果和提交状态。
docs/ai/constraints/
记录全局约束、项目约束,以及后续可扩展的语言/框架约束。
这组文档的本质作用是:给 AI 提供稳定、低歧义、可持续更新的上下文锚点。
.claude/:行为定义层
这部分是真正驱动 Claude Code CLI 工作方式的地方:
.claude/commands/
定义每个工作流命令的职责、输入边界和输出要求。
.claude/skills/
定义可复用的行为模块,例如目标发现、方案设计、约束加载、安全扫描、同步回写。
.claude/agents/
定义面向局部分析任务的专用代理,例如设计审查、安全审查、影响范围分析、死代码复核。
如果把整个项目理解成一个工作流系统,那么:
-
commands是入口层 -
skills是执行层 -
agents是分析辅助层
核心设计原则
1. 长期规划与当前执行分离
roadmap.md 和 current-goal.md 是整个系统最重要的一组拆分。
-
roadmap.md负责稳定信息:总体目标、阶段拆分、依赖、完成状态 -
current-goal.md负责短周期信息:当前目标、设计决策、测试计划、实施步骤
这能避免所有内容都堆在一个文档里,也避免 AI 在每次执行时把长期规划和步骤细节混在一起。
2. 任意时刻只能有一个当前目标
ClaudeDevKit 明确限制:同一时刻只允许存在一个活跃的 current goal。
原因很简单。AI 的上下文能力很强,但项目执行需要聚焦。多个并行目标会让设计边界、验收条件和测试范围迅速模糊,最终导致“样样都提到,样样都没收敛”。
3. 先澄清和设计,再进入实现
/ai-goal 的命令说明里明确规定:
-
先检查当前工作区和现有目标状态
-
没有目标时先生成候选方案
-
用户选择后再补全设计
-
只有在用户确认方案后,才能进入实现
这实际上把“不要一上来就写代码”从一种建议,变成了工作流约束。
4. 文档是共享状态,不是附属产物
在很多项目里,文档是实现后的附属物。而在这个工作流里,文档本身就是 AI 协作的一部分。
例如:
-
路线图更新不是“有空再写”,而是后续目标判断的依据
-
当前目标设计不是“补充说明”,而是实现前置条件
-
change-log不是面向发布才写,而是同步流程的一部分
这使得 AI 不是只消费代码上下文,而是同时消费项目状态上下文。
命令系统:工作流的主入口
.claude/commands/ 下定义了整个工作流的主要入口。它们不是随意组合的命令菜单,而是按项目生命周期划分的控制面。
/ai-help
作用:展示当前工作流状态、命令清单,以及最推荐的下一步操作。
它会读取 docs/ai/ 中的默认状态文件,并根据当前状态做推荐。例如:
-
仓库尚未初始化时推荐
/ai-init -
文档摘要过期时推荐
/ai-scan -
没有活跃目标时推荐
/ai-goal -
目标验证完成但尚未同步时推荐
/ai-sync
这个命令的特点是偏路由,不直接改业务内容,而是帮助开发者判断流程位置。
/ai-ask
作用:严格只读的问答入口。
它的边界很明确:
-
可以读代码、配置、文档、工作流状态
-
可以解释仓库结构和行为
-
不允许修改任何文件
-
不允许更新工作流状态
-
不允许触发同步、提交、推送等写操作
这个命令适合用来做仓库解释、定位问题、理解某个设计决定,而不改变任何状态。
/ai-init
作用:初始化或修复 AI 工作流骨架。
它负责:
-
检查
docs/ai和.claude/{commands,skills,agents}是否存在 -
在缺失时恢复工作流骨架
-
在空仓库或近似空仓库时,接受技术路线图文档作为初始化输入
-
从路线图中提取总体目标、模块规划、里程碑、约束和候选目标
它不会做的事情也很关键:
-
不自动选择第一个当前目标
-
不自动生成业务代码
-
不覆盖已有的有效项目内容
这说明它本质上是“项目工作流初始化器”,而不是“代码脚手架生成器”。
/ai-adopt
作用:把这套 AI 工作流安全嵌入到一个已有项目中。
它的重点不在创建,而在“识别现状并谨慎接入”。命令定义里明确要求它:
-
判断项目是否适合接入
-
扫描仓库结构、入口、配置和测试面
-
检查是否已经存在
.claude/或docs/ai/ -
区分哪些文件可以安全创建,哪些更新必须征求确认
-
生成 2-3 个候选当前目标,但不自动进入实现
这使得 ClaudeDevKit 具备嵌入现有项目的能力,而不是只适合新仓库。
/ai-scan
作用:刷新仓库摘要层。
它主要更新两个文件:
-
docs/ai/project-summary.md -
docs/ai/project-tree.md
这个命令的价值在于:它把“真实仓库结构”重新映射回 AI 共享上下文,减少文档与代码结构脱节的问题。
/ai-roadmap
作用:维护长期路线图。
它负责更新 docs/ai/roadmap.md 中的目标、顺序、依赖、状态和备注,并要求在修改前读取当前目标状态,确保长期路线和当前目标不打架。
它适合做这些事:
-
新增目标
-
调整优先级
-
修改阶段划分
-
标记目标完成或废弃
/ai-goal
作用:驱动当前目标从发现、设计到确认的整个过程。
这是这套工作流里最关键的命令之一。它会:
-
检查当前工作区和现有状态
-
在没有活跃目标时生成候选选项
-
在用户选择后补全设计,包括范围、验收条件、测试计划和步骤
-
把确认后的设计写回
docs/ai/current-goal.md -
更新
docs/ai/current-goal.state.yaml -
在用户确认前不进入实现
这个命令把“目标管理”和“实现入口”连在了一起,是工作流的主控制枢纽。
/ai-check
作用:对活跃目标做健康检查。
检查项包括:
-
工作流文件是否缺失或过期
-
current-goal.md和current-goal.state.yaml是否一致 -
是否缺少验收标准或测试计划
-
实现是否偏离项目约定
-
是否存在应阻止同步的安全问题
-
是否存在仍然阻塞实现的开放问题
这个命令的作用不是“再解释一遍目标”,而是对流程完整性和设计一致性做审查。
/ai-deadcode
作用:检测高置信死代码。
它的策略很保守,只要求高置信发现,重点看:
-
不可达代码
-
无引用代码
-
明显与当前项目目标无关的实现
它不会自动删除代码,而是要求先报告:
-
位置
-
证据
-
置信度
-
移除风险
-
建议动作
然后再由用户决定是现在清理、暂时保留,还是转成后续路线图项。
/ai-security
作用:扫描硬编码敏感信息和明显安全问题。
重点关注:
-
API keys
-
access tokens
-
private keys
-
明文密码
-
配置文件和容器文件中的敏感值泄露
这个命令既可以单独使用,也可以为 /ai-check 和 /ai-sync 提供阻塞判断。
/ai-sync
作用:在当前目标完成并验证后,把结果同步回工作流状态。
它会更新:
-
roadmap.md -
current-goal.md -
current-goal.state.yaml -
change-log.md
同时它还要求:
-
确认相关测试已通过
-
补充安全和死代码检查结果
-
生成建议的 commit message
-
在提交或推送前,必须取得用户明确确认
这个命令确保“实现完成”不会停留在代码层,而是真正回写到项目状态层。
Skills:命令背后的可复用行为模块
如果说 commands 定义的是“要做什么”,那么 skills 定义的就是“具体怎么做”。
这层设计的好处是:命令不需要内嵌所有细节,而是可以按职责调用可复用模块。
constraints-loader
职责:加载人类维护的约束文件。
加载顺序是:
-
docs/ai/constraints/global.md -
对应语言约束
-
对应框架约束
-
docs/ai/constraints/project.md
这使得整个工作流有一个清晰的约束注入点,避免每个命令自己重复推断规则。
help-router
职责:支撑 /ai-help。
它负责:
-
读取当前工作流状态
-
生成命令总览表
-
用简洁自然语言说明当前状态
-
推荐最合适的下一个命令
这个 skill 本质上是一个工作流导航器。
read-only-qa
职责:支撑 /ai-ask 的只读问答能力。
它把“可读但不可写”的边界明确下来,适合做解释型问答,避免误触写操作。
goal-discovery
职责:支撑 /ai-goal 在目标尚未明确时的发现阶段。
它会检查:
-
当前仓库状态
-
工作流文件是否完整
-
是否已有活跃目标
-
当前请求是否缺少足够上下文
最终输出当前状态、缺口、阻塞和建议下一步。
goal-design
职责:在用户选定方向后,把目标扩展成可执行设计。
它要求写清楚:
-
范围与非范围
-
验收标准
-
测试计划
-
实现步骤
-
明确任务列表
并在进入实现前把状态推进到 confirm_plan。
tdd-execution
职责:约束实现阶段遵循 TDD。
规则包括:
-
尽可能从失败或缺失的测试开始
-
测试范围必须绑定当前目标
-
在测试更新和实现更新之间迭代
-
不能在相关测试未通过时宣称完成
这个 skill 的意义是把“测试优先”从口头原则落到执行规范上。
project-fit-check
职责:检查改动是否真正融入现有项目,而不是生成孤立实现。
它重点发现:
-
重复抽象
-
绕开项目约定
-
一次性模块
-
命名和分层不一致
这对 AI 编码特别重要,因为 AI 很容易为了完成局部任务而创建一个看似有效、但长期不适合维护的平行实现。
project-adoption
职责:支撑 /ai-adopt 在已有仓库中接入工作流。
它会判断仓库当前处于:
-
not_adopted -
partial -
adopted -
conflict
并给出紧凑的 adoption report,帮助用户决定下一步是继续接入、先清冲突,还是直接进入目标设计。
security-secrets-scan
职责:扫描高置信敏感信息泄露风险。
它会输出:
-
位置
-
问题类型
-
置信度
-
修复建议
-
是否应阻止 commit 或 push
它既是独立安全检查模块,也是同步前的安全闸门。
dead-code-detection
职责:识别高置信死代码。
它默认只关注高置信场景,避免把“暂时没引用但仍有价值”的代码误判为垃圾。
sync-and-history
职责:支撑 /ai-sync 做状态回写。
它负责:
-
更新路线图表格
-
更新当前目标状态
-
追加简洁事实型变更记录
-
保证同步结果与测试状态一致
这让同步不只是“写个日志”,而是系统地维护长期状态。
Agents:面向局部问题的专用分析角色
相比 skills 负责流程内执行,.claude/agents/ 更像是给复杂分析任务准备的专用审查角色。
它们目前主要有四个:
design-reviewer
职责:在实现前审查目标设计。
它关注:
-
是否存在模糊实现选择
-
是否缺少验收标准
-
是否缺少测试策略
-
是否没有很好地融入现有项目
它的输出要求是“问题优先”,并按严重程度排序。
impact-mapper
职责:为较大目标映射影响范围。
它会分析:
-
可能受影响的模块
-
可能需要修改的文件
-
需要更新的测试区域
-
不能被绕开的集成点
这对较大仓库尤其有价值,因为它帮助 AI 在改动前先建立影响面认知。
security-reviewer
职责:在同步或发布前复核敏感信息和明显安全风险。
它更像是对安全结果做保守复核,明确哪些问题是阻塞项,以及最稳妥的修复路径。
dead-code-reviewer
职责:复核死代码发现结果。
它的重点不是“多发现一些”,而是尽量避免误报。它会判断:
-
是否真的不可达或无引用
-
是否存在误判
-
移除风险多大
-
应该立刻清理、延后处理,还是转成路线图事项
一个典型的工作流闭环
把这些命令、skills 和 agents 组合起来后,一个典型流程大致是这样的:
-
新项目或空项目先用
/ai-init -
已有项目接入时先用
/ai-adopt -
用
/ai-scan刷新项目摘要和树结构 -
用
/ai-roadmap确认长期方向和阶段目标 -
用
/ai-goal选定并设计当前目标 -
用
/ai-check在实现前或实现中做流程健康检查 -
视情况运行
/ai-security和/ai-deadcode -
当前目标相关测试通过后,用
/ai-sync回写状态和历史 -
在用户明确确认后,才允许 commit 和 push
这个流程的重点在于,它把 AI 的参与限制在一条可追踪路径上,而不是让 AI 自由漫游在代码库里。
这个项目的实际价值
从实践角度看,ClaudeDevKit 当前最有价值的地方不是“功能很多”,而是它把几件关键事情固定下来了:
-
AI 围绕哪些文档工作
-
什么信息属于长期状态,什么信息属于当前执行
-
什么阶段可以进入实现
-
什么检查会阻止同步和提交
-
什么结果必须回写到项目状态里
这意味着它虽然轻,但已经具备一个最小可用的工程化闭环。